10.2. Using Branches Effectively¶
Besides taking snapshots of your work and backing it up, version control also lets you manage multiple versions of a project’s code base simultaneously, for example, to allow part of the team to work on an experimental new feature without disrupting working code, or to fix a bug in a previously-released version of the code that some customers are still using.
Branches are designed for such situations. Rather than thinking of commits as just a sequence of snapshots, we should instead think of a directed, acyclic graph of commits. When a new repo is created, by default it contains only a single branch, usually called the main branch, on which a linear sequence of commits is made. At any point in time, a new branch can be created that “splits off” from any commit of an existing branch, creating a copy of the code tree as it exists at that commit. As soon as a branch is created, that branch and the one from which it was split are separate: commits to one branch don’t affect the other, though depending on project needs, commits in either may be merged back into the other. Indeed, branches can even be split off from other branches, but overly complex branching structures offer few benefits and are difficult to maintain. Finally, unlike a real tree branch, a repo branch can be merged back into another branch later—either the branch from which it split off, or some other branch. A branch can also be deleted, for example, if the project decides to abandon the work-in-progress that branch represents.
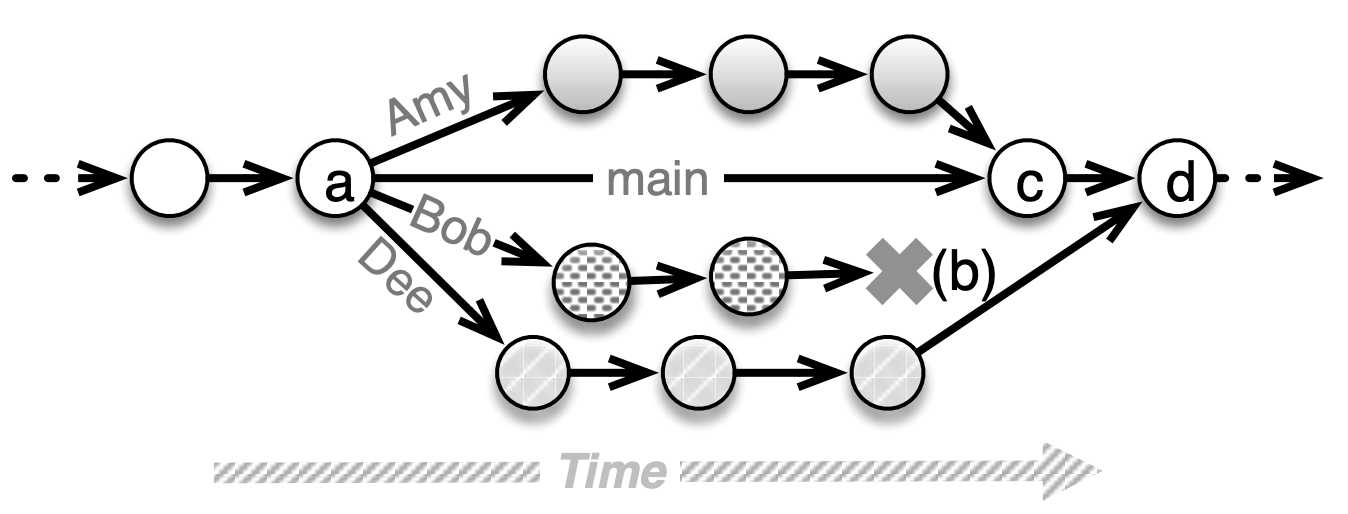
We highlight two common branch management strategies that can be used together or separately, both of which strive to ensure that the main branch always contains a stable working version of the code. Figure 10.2 shows a feature branch, which allows a developer or sub-team to make the changes necessary to implement a particular feature without affecting the main branch until the changes are complete and tested. If the feature is merged into the main branch and a decision is made later to remove it (perhaps it failed to deliver the expected customer value), the specific commits related to the merge of the feature branch can sometimes be undone, as long as there haven’t been many changes to the main branch that depend on the new feature.
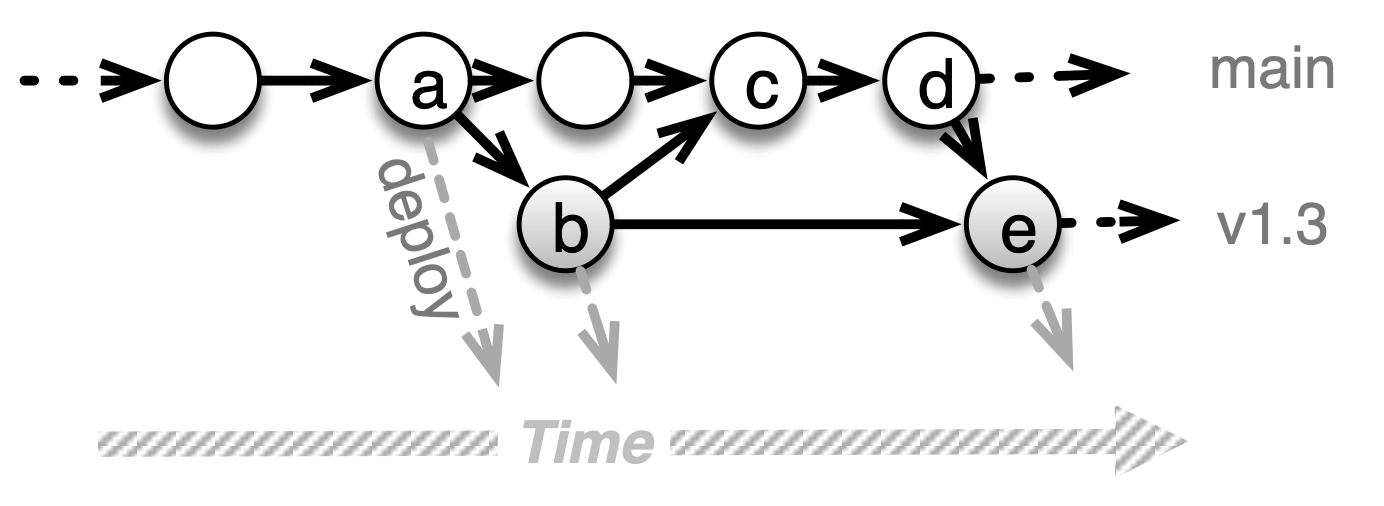
Figure 10.3 shows how release branches are used to fix problems found in a specific release. They are widely used for delivering non-SaaS products such as libraries or gems whose releases are far enough apart that the main branch may diverge substantially from the most recent release branch. For example, the Linux kernel, for which developers check in thousands of lines of code per day, uses release branches to designate stable and long-lived releases of the kernel. Release branches often receive multiple merges from the development or main branch and contribute multiple merges to it. Release branches are less common in delivering SaaS because of the trend toward continuous integration/continuous deployment (Section 1.4): if you deploy several times per week, the deployed version won’t have time to get out of sync with the main branch, so you might as well deploy directly from the main branch. We discuss continuous deployment further in Chapter 12.
Figure 10.4 shows some commands for manipulating Git branches. At any given time, the current branch is whichever one you’re working on in your copy of the repo. Since in general each copy of the repo contains all the branches, you can quickly switch back and forth between branches in the same repo (but see Fallacies and Pitfalls for an important caveat about doing so).

Small teams working on a common set of features commonly use a shared-repository model for managing the repo: one particular copy of the repo, referred to as the origin repo, is designated as authoritative, and all developers agree to push their changes to the origin and periodically pull from the origin to get others’ changes. Famously, Git itself doesn’t care which copy of the repo is authoritative—any developer can pull changes from or push changes to any other developer’s copy of that repo if the repo’s permissions are configured to allow it—but for small teams, it’s convenient (and conventional) for the origin repo to reside in the cloud on a service such as GitHub. Each team member can clone the origin repo onto their development computer, do their work, make their commits on their local clone, and periodically push their commits to the origin. From the point of view of each developer’s local clone, the origin is one of possibly several remote copies of the repo, or simply “remotes.” In the shared-repository model, the origin repo is usually the only remote. Section 10.4 describes scenarios in which there may be multiple remotes.
As Figure 10.4 shows, the git push and git pull commands usually specify which copy of the
repository and which branch should be involved in a push or pull operation. If Amy commits
changes to her clone of the repo, those changes aren’t visible to her teammate Bob until
she does a push and Bob does a pull.
This raises the possibility of a merge conflict scenario. Returning to Figure 10.2, suppose that
Dee’s feature branch results in changes to some of the same files as Amy’s feature branch. At
the commit marked (c), Amy has successfully merged her changes into the main branch. When Dee
tries to push her changes (d), she will initially be prevented from doing so because additional
commits have occurred in the origin repo since she last pulled (probably at point (a) when
creating her branch). Dee must bring her copy of the repo up-to-date with respect to the origin
before she can push her changes. One way to do this is for her to switch back to her main branch,
then run git pull origin main to get the latest commits on main from the origin repo; her copy
of the repo now looks the same as it looked to Amy right after point (c). Now Dee can try to merge
her branch changes back into main. If Dee’s branch changes different files than Amy’s branch, or
if they change different parts of the same file that are far apart, the merge will succeed and
Dee can then push her merged main branch back to the shared repo (git push origin main).
Roses are red,
Violets are blue.
<<<<<<< HEAD:poem.txt
I love GitHub,
=======
ProjectLocker rocks,
>>>>>>> 77976da35a11db4580b80ae27e8d65caf5208086:poem.txt
and so do you.
But if Dee and Amy had edited parts of the same file that were within a few lines of each other, as in Figure 10.5, Git will conclude that there is no safe way to automatically create a version of the file that reflects both sets of changes, and it will leave a conflicted and uncommitted version of the file with conflict markers (<<< and >>>) in Dee’s main branch. Dee must now manually edit that file and add and commit the manually edited version to complete the merge, after which she can push the merged main back to the shared repo. In the next section, we will discuss an alternative process for preventing merge conflicts before they occur. If a merge goes badly awry, Figure 10.6 provides some mechanisms for partially or fully undoing the results of the merge. Figure 10.7 lists some useful Git commands to help keep track of who did what and when. Figure 10.8 shows some convenient notational alternatives to the cumbersome 40-digit Git commit-IDs.
Finally, don’t overlook the importance of a scratch branch, which is a branch that is never intended to be merged back into the mainline code. You can create a scratch branch to explore code changes such as exploring a spike (Section 7.4) or dry-running a radical change such as upgrading to a major new version of your app framework.
Whichever branches you create, if those branches are pushed to the main repo, over time the number of branches will grow. GitHub has a user interface for viewing and pruning stale (inactive) branches, which helps keep your codebase manageable.
Self-Check 10.2.1. Describe a scenario in which merges could go in both directions—changes in a feature branch merged into the main branch, and changes in the main branch merged into a feature branch. (In Git, this is called a crisscross merge.)
Diana starts a new branch to work on a feature. Before she completes the feature, an important bug is fixed and the fix is merged into the main branch. Because the bug is in a part of the code that interacts with Diana’s feature, she merges the fix from main into her own feature branch. Finally, when she finishes the feature, her feature branch is merged back into main.