9.5. Metrics, CodeSmells, and SOFA¶
1. Declining Quality - The quality of [software] systems will appear to be declining unless they are rigorously maintained and adapted to operational environment changes.
—Lehman’s seventh law of software evolution
A key theme of this book is that engineering software is about creating not just working code, but beautiful working code. This chapter should make clear why we believe this: beautiful code is easier and less expensive to maintain. Given that software can live much longer than hardware, even engineers whose aesthetic sensibilities aren’t moved by the idea of beautiful code can appreciate the practical economic advantage of reducing lifetime maintenance costs.

How can you tell when code is less than beautiful, and how do you improve it? We’ve all seen examples of code that’s less than beautiful, even if we can’t always pin down the specific problems. We can identify problems in two ways: quantitatively using software metrics and qualitatively using code smells. Both are useful and tell us different things about the code, and we apply both to the ugly code in Figure 9.6.
Software metrics **are quantitative measurements of code complexity, which is often an estimate of the difficulty of thoroughly testing a piece of code. Dozens of metrics exist, and opinion varies widely on their usefulness, effectiveness, and “normal range” of values. Most metrics are based on the **control flow graph of the program, in which each graph node represents a basic block (a set of statements that are always executed together), and an edge from node A to node B means that there is some code path in which B’s basic block is executed immediately after A’s.
Figure 9.10 shows the control flow graph corresponding to Figure 9.6, which we can use to compute two widely-used indicators of method-level complexity:
Cyclomatic complexity measures the number of linearly-independent paths through a piece of code.
ABC score is a weighted sum of the number of Assignments, Branches and Conditionals in a piece of code.
These analyses are usually performed on source code and were originally developed for
statically-typed languages. In dynamic languages, the analyses are complicated by
metaprogramming and other mechanisms that may cause changes to the control flow graph at
runtime. Nonetheless, they are useful first-order metrics, and as you might expect, the
Ruby community has developed tools to measure them. saikuro computes a simplified version
of cyclomatic complexity and flog computes a variant of the ABC score that is weighted in
a way appropriate for Ruby idioms. Both of these and more are included in the metric_fu
gem (part of the courseware). Running rake metrics on a Rails app computes various metrics
including these, and highlights parts of the code in which multiple metrics are outside
their recommended ranges. In addition, CodeClimate provides many of these metrics as a
service: by creating an account there and linking your GitHub repository to it, you can
view a “report card” of your code metrics anytime, and the report is automatically updated
when you push new code to GitHub. Figure 9.11 summarizes useful metrics we’ve seen so far
that speak to testability and therefore to code beauty.

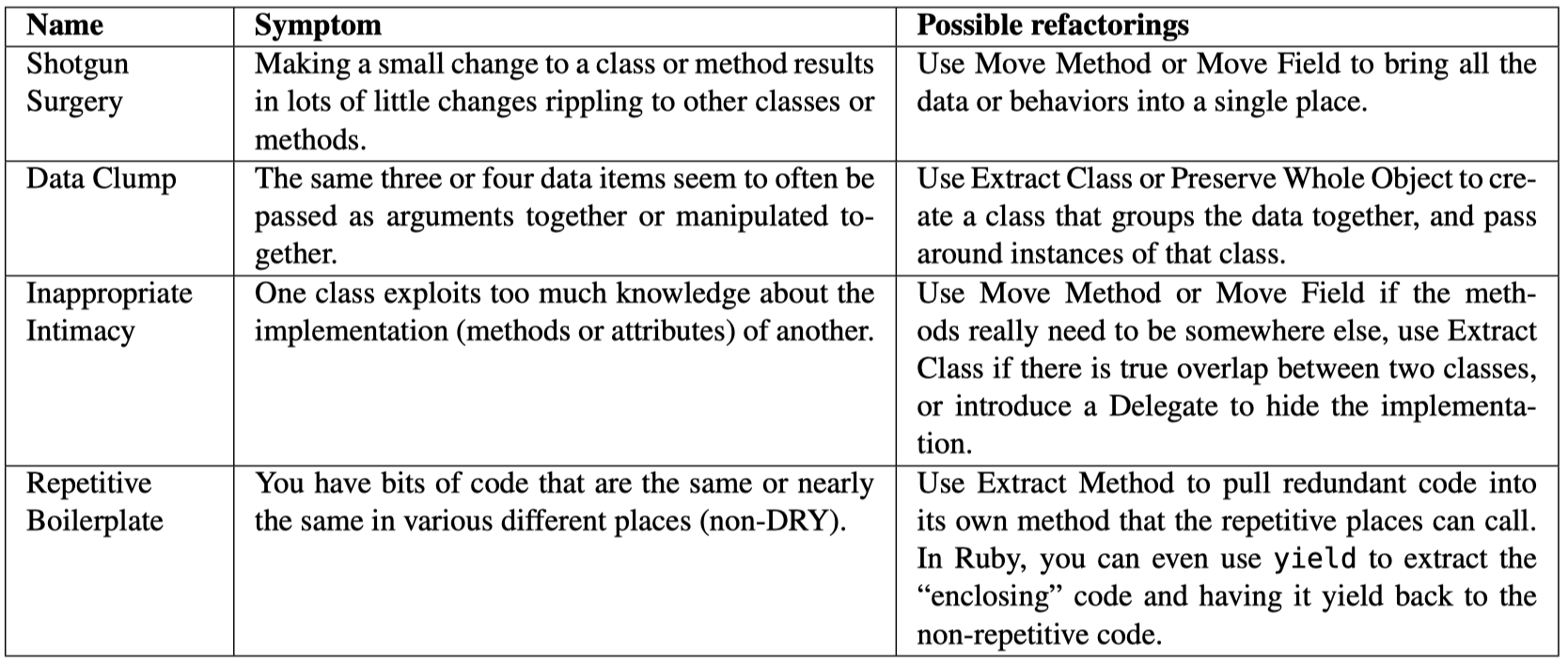
The second way to spot code problems is by looking for code smells, which are structural characteristics of source code not readily captured by metrics. Like real smells, code smells call our attention to places that may be problematic. Martin Fowler’s classic book on refactoring (Fowler et al. 1999) lists 22 code smells, four of which we show in Figure 9.12, and Robert C. Martin’s Clean Code (Martin 2008) has one of the more comprehensive catalogs with an amazing 63 code smells, of which three are specific to Java, nine are about testing, and the remainder are more general.
Four particular smells that appear in Martin’s Clean Code are worth emphasizing, because they are symptoms of other problems that you can often fix by simple refactorings. These four are identified by the acronym SOFA, which states that a well-written method should:
be Short, so that its main purpose is quickly grasped;
do only One thing, so testing can focus on thoroughly exercising that one thing;
take Few arguments, so that all-important combinations of argument values can be tested;
maintain a consistent level of Abstraction, so that it doesn’t jump back and forth between saying what to do and saying how to do it.

Figure 9.6 violates at least the first and last of these, and exhibits other smells as well, as we can see by running reek on it:
time_setter.rb -- 5 warnings:
TimeSetter#self.convert calls (y + 1) twice (Duplication)
TimeSetter#self.convert has approx 6 statements (LongMethod)
TimeSetter#self.convert has the parameter name 'd' (UncommunicativeName)
TimeSetter#self.convert has the variable name 'd' (UncommunicativeName)
TimeSetter#self.convert has the variable name 'y' (UncommunicativeName)
Not DRY (line 2). Admittedly this is only a minor duplication, but as with any smell, it’s worth asking ourselves why the code turned out that way.
Uncommunicative names (lines 4–6). Variable y appears to be an integer (lines 6, 7, 10, 14)
and is related to another variable d —what could those be? For that matter, what does the
class TimeSetter set the time to, and what is being converted to what in convert? Four
decades ago, memory was precious and so variable names were kept short to allow more space
for code. Today, there’s no excuse for poor variable names; Figure 9.13 provides suggestions.
Too long (line 3). More lines of code per method means more places for bugs to hide, more
paths to test, and more mocking and stubbing during testing. However, excessive length is
really a symptom that emerges from more specific problems—in this case, failure to stick
to a single level of Abstraction. As Figure 9.14 shows, convert really consists of a small
number of high-level steps, each of which could be divided into sub-steps. But in the code,
there is no way to tell where the boundaries of steps or sub-steps would be, making the method
harder to understand. Indeed, the nested conditional in lines 6–8 makes it hard for a programmer
to mentally “walk through” the code, and complicates testing since you have to select sets of
test cases that exercise each possible code path.
start with Year = 1980
while (days remaining > 365)
if Year is a leap year
then if possible, peel off 366 days and advance Year by 1
else
peel off 365 days and advance Year by 1
return Year
As a result of these deficiencies, you probably had to work hard to figure out what this relatively simple method does. (You might blame this on a lack of comments in the code, but once the above smells are fixed, there will be hardly any need for them.) Astute readers usually note the constants 1980, 365, and 366, and infer that the method has something to do with leap years and that 1980 is special. In fact, convert calculates the current year given a starting year of 1980 and the number of days elapsed since January 1 of that year, as Figure 9.14 shows using simple pseudocode. In Section 9.5, we will make the Ruby code as transparent as the pseudocode by refactoring it—applying transformations that improve its structure without changing its behavior.
A few specific examples of doing one thing are worth calling out because they occur frequently:
Handling an exception is one thing. If method \(M\) computes something and also tries to handle various exceptions that could arise while doing so, consider splitting out a method \(M'\) that just does the work, and having \(M\) do exception handling and otherwise delegate the work to \(M'\).
Queries (computing something) and commands (doing something that causes a side effect) are distinct, so a method should either compute something that is side-effect- free or it should cause a specific side effect, but not both. Such violations of command–query separation also complicate testing.
Self-Check 9.5.1. Give an example of a dynamic language feature in Ruby that could distort metrics such as cyclomatic complexity or ABC score.
Any metaprogramming mechanism could do this. A trivial example is
s="if (d>=366)[...]"; eval s,since the evaluation of the string would cause a conditional to be executed even though there’s no conditional in the code itself, which contains only an assignment to a variable and a call to theevalmethod. A subtler example is a method such asbefore_filter(Section 5.1), which essentially adds a new method to a list of methods to be called before a controller action.
Self-Check 9.5.2. Which SOFA guideline—be Short, do One thing, have Few arguments, stick to a single level of Abstraction—do you think is most important from a unit-testability point of view?
Few arguments implies fewer ways that code paths in the method can depend on the arguments, making testing more tractable. Short methods are certainly easier to test, but this property usually follows when the other three are observed.